
In what can be described as perfect timing, Sepherosa Ziehau has produced a document comparing FreeBSD, several different Linux kernels, and DragonFly, for networking. He’s presenting it in the afternoon track of Day 3 for AsiaBSDCon 2017, starting later this week.
He’s published a snippet as a PDF (via), which includes some graphs. The one place Linux outperforms DragonFly seems to be linked to the Linux version of the network card driver being able to access more hardware – so DragonFly should be comparable or better there too, once the powers-of-2 problem is solved. (This already came up in comments to a post last week.)
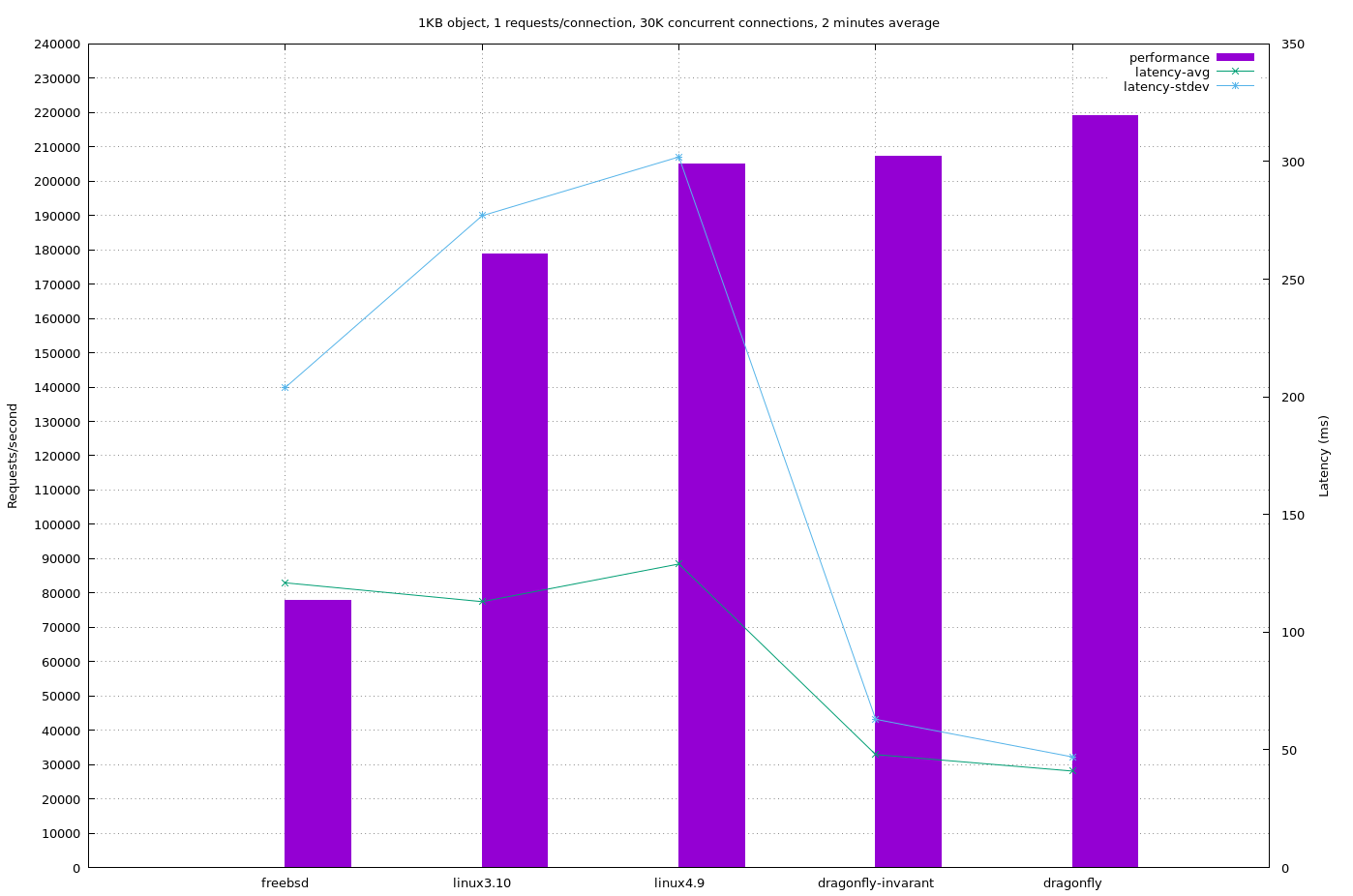
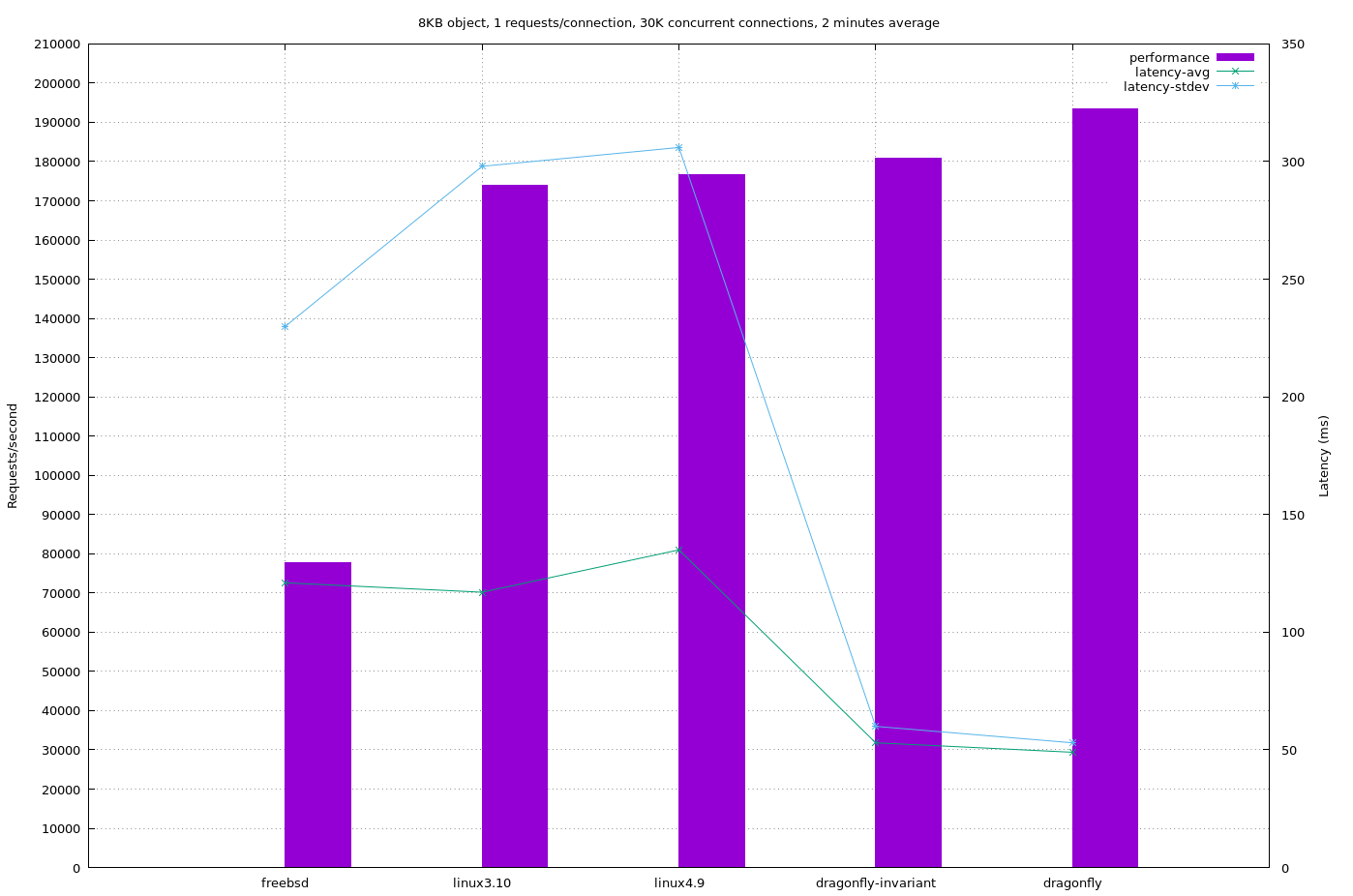
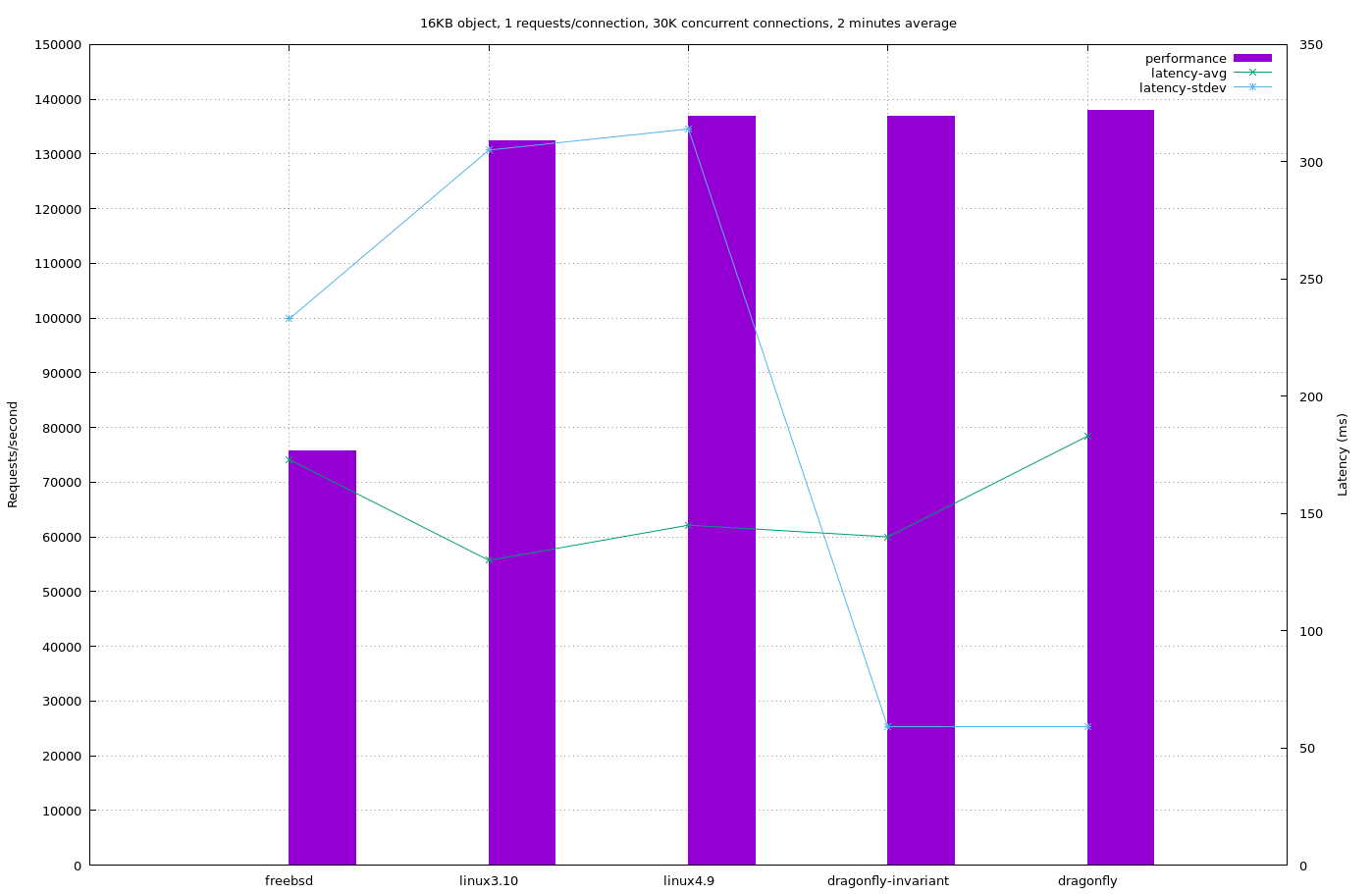
Those graphs are available standalone, too, which means it’s easier to see the fantastic performance for latency – see the thin blue line – that seems exclusive to DragonFly. That, if anything, is the real takeaway; that DragonFly’s model has benefits not just to plain speed but to the system’s responsiveness under load. “My CPU is maxed out cause I’m doing a lot of work but I hardly notice” is a common comment over the past few years – and now we can see that for network performance, too.
{kind=link}
{kind=link}
{kind=link}
@Justin
>>”That, if anything, is the real takeaway; that DragonFly’s model has benefits not just to plain speed but to the system’s responsiveness under load.”
Is that an accurate conclusion?
The takeaway to me seems to be:
1. Lock based (Linux) and Lockless (Dragonfly) implementations has no impact on overall throughout.
2. Dragonfly has a smaller standard deviation of what latency will exist. Said another, latency is more consistent with Dragonfly than with Linux.
3. Linux has more throughput for non powers of 2 based systems. (E.g. 24 cores).
4. The myth that FreeBSD was best for networking is false. It’s worst.
Francis: The older and newer Linux implementations are locking and lockless, and there’s a definite performance difference, which at least suggests though does not prove that it makes a difference.
I understand what you say about latency being consistent – but it is also lower, which I think is the real positive feature.
As for FreeBSD being worst – it’s not doing well in this benchmark, *but* this is a very specific benchmark, with all the caveats that implies.
“Francis: The older and newer Linux implementations are locking and lockless, and there’s a definite performance difference, which at least suggests though does not prove that it makes a difference.”
JUSTIN:
Are you suggesting that Linux 3.10 is lock-based and Linux 4.9 is lockless?
If so, that’s major news. I must of missed the fact that Linux now is lockless
https://leaf.dragonflybsd.org/~sephe/perf_cmp.pdf
@Vijay, yes Linux TCP stack has been lockless since kernel 4.4.
I agree the perf PDF slides should be updated since slide # 1 makes it seems only dragonflybsd is lockless and all others are lock based.
More info on Linux being lockless
https://lwn.net/Articles/659199/
Actually it’s interesting comparing the different workloads (object size). Yes, in raw numbers FreeBSD fares worst, but it doesn’t change that much while the other ones show a big change. DF at 220K for 1KB drops to a little under 140K for 16KB. The others show similar, with FBSD dropping from say 77000 to 75000.
Performance stuff is always interesting.
On the last slide of the performance benchmark it says that Linux can use all 64 rings ( but it was not tested as such)
I really wonder what the performance chart would look lot if all 64 rings had been test.
Linux might be 4x the performance of Dragonfly … which would be disingenuous to not include that if it’s the case.
Linux seems to scale as other have said linearly at a rate of 0.5Mpps/ring.
So Linux with 64 rings might be 32Mpps, where as Dragonfly was on 8Mpps.
If you had a 64-thread machine then 64 rings could potentially scale performance further, up to the wire-line cap. There are still a lot of assumptions there (you have to have 64 MSI-X vectors and the firmware on the chipset has to be able to handle that many rings efficienctly too). DragonFly is perfectly capable of handling 64, actualy, since 64 is a power of 2 its actually easier than handling 24.
The point on the graphs showing 16 vs 24 is that the linux driver is using a mode that is not well documented to get to 24. The DFly driver is using what at the time we thought was the chipset limit as described by the chipset documentation. In order to use the mode on DFly we will have to make adjustments to the way the kernel maps the hash. Currently we use a simple mask (hence the power-of-2 requirement). That will have to change to a table lookup in order to map to a non-power-of-2 number of rings.
Generally speaking, scaling the number of rings past available cpu threads should not lead any real improvement in performance. If you have a 16-thread machine then 64 rings won’t do any better than 16 rings, for example. The issue with the number of rings is entirely a cpu localization issue. The number of rings alone does not imply scale.
-Matt
Thanks Matt for the detailed response.
Much appreciated.
Do we understand the times we live? CPU became the bottleneck. Are others bothering with stuff near the hard work deployed behind dfly’s network stack and related? I DON”T THINK SO! Think pc to pc cheap (hundred bucks) year201X ethernet connection. Why will I need insane amounts of threads just to have that? FreeBSD, Linux, etc, they all want something near or close to wire speed 14.88 Mpps on one thread! Enter network stack bypassing solutions, dpdk, netmap/ptnetmap, vale software switch in freeBSD. Linux went further, they want to have something that isn’t run from userland, as in: it isn’t bypassing the kernel or the tcp/ip stack, but it runs in concert with it. It is called XDP (eXpress Data Path) and it works with something that isn’t yet in DragonflyBSD for reasons Sephe explained already at least two times, I am talking about the Mellanox InfiniBand cards, the ones that use the mlx4 driver, for example, since I can’t think of something cheaper that is rated 40Gbit/s!
https://people.netfilter.org/hawk/presentations/xdp2016/xdp_intro_and_use_cases_sep2016.pdf
also read:
https://2016.eurobsdcon.org/PresentationSlides/NanakoMomiyama_TowardsFastIPForwarding.pdf
https://events.linuxfoundation.org/sites/events/files/slides/pushing-kernel-networking.pdf
https://people.netfilter.org/hawk/presentations/nfws2016/nfws2016_next_steps_for_linux.pdf
https://people.netfilter.org/hawk/presentations/xdp2016/xdp_intro_and_use_cases_sep2016.pdf
https://www.iovisor.org/technology/xdp
@Jared
Thank you very much, I will update my presentation.
xdp is just another netmap/dpdk work-alike, which bypasses kernel network stack and directly operates on the NICs. Other folks may be interested to complete the netmap port (we did have netmap imported but never finished), but not me; I’d focus on improving the kernel network stack.
My experiences: Routing in DF is slower than in FBSD.